Vous n'êtes pas identifié(e).
- Contributions: Récentes | Sans réponse
#1 12-02-2024 17:25:38
- Climax
- Administrateur

- Inscription: 30-08-2008
- Messages: 6 471


Comment concevoir un algorithme de prévision des taux de change ?

La conception d'un algorithme de prévision des taux de change implique une série d'étapes qui intègre des connaissances en finance, en économie, en mathématiques, en programmation et en apprentissage automatique.
Points clés :
➡️ Intégrer des variables pertinentes : Inclure des indicateurs macroéconomiques clés tels que les taux d'intérêt, l'inflation, le PIB et la stabilité politique, car ils influencent tous les taux de change. (Ce que vous incluez dépend de votre stratégie).
➡️ Utiliser des modèles statistiques avancés : Utilisez des analyses de séries chronologiques, des algorithmes d'apprentissage automatique et des modèles économétriques pour saisir les relations complexes dans les données financières.
➡️ Validation et test rigoureux : Mettez en œuvre des stratégies robustes de backtesting et de validation pour garantir la précision et la fiabilité de l'algorithme dans différentes conditions de marché.
➡️ Modèle d'exemple : Nous donnons un exemple au bas de cet article d'un type d'approche utilisant des données synthétiques.
Voici les grandes lignes du processus :
Définir l'objectif
Formulez clairement l'objectif de l'algorithme.
S'agit-il de prévoir les fluctuations à court terme ou les tendances à long terme des taux de change ?
Il est important de comprendre l'horizon de trading, d'investissement ou opérationnel.
Collecte et prétraitement des données
Sources de données
Identifier et collecter les données pertinentes.
Il s'agit notamment des taux de change historiques, des indicateurs macroéconomiques (comme le PIB, les taux d'inflation, les taux d'intérêt), des événements politiques et des données sur le sentiment du marché.
Nettoyage des données
Traiter les valeurs manquantes, les valeurs aberrantes et les incohérences dans les données.
Ingénierie des caractéristiques
Créer de nouvelles caractéristiques susceptibles d'être utiles à la prédiction, telles que des moyennes mobiles, des variables décalées ou des indicateurs dérivés de données textuelles (par exemple, l'analyse du sentiment des articles de presse).
Analyse exploratoire des données (AED)
Analyser les données pour découvrir des modèles, des tendances et des corrélations.
Utiliser des visualisations pour comprendre les relations entre les variables.
Effectuer des tests statistiques pour valider les hypothèses sur les données.
Sélection de modèles
Choisir les modèles appropriés en fonction de la nature des données et de l'objectif de prédiction.
Les options comprennent les modèles de régression linéaire, les modèles de séries temporelles (comme ARIMA), les algorithmes d'apprentissage automatique (comme Random Forest, SVM, les réseaux neuronaux), et les techniques avancées comme les réseaux LSTM (Long Short-Term Memory) pour la prédiction de séquences.
Sélection des caractéristiques et réduction de la dimensionnalité
Identifier les caractéristiques les plus pertinentes pour le modèle.
Appliquer des techniques telles que l'ACP (analyse en composantes principales) pour la réduction de la dimensionnalité si nécessaire.
Formation et validation du modèle
Divisez les données en deux ensembles, l'un pour la formation et l'autre pour le test.
Entraînez le modèle sur l'ensemble d'entraînement et validez ses performances sur l'ensemble de test.
Utilisez des mesures telles que RMSE (Root Mean Square Error), MAE (Mean Absolute Error) et AIC (Akaike Information Criterion) pour l'évaluation du modèle.
Réglage des hyperparamètres
Optimisez le modèle en ajustant ses hyperparamètres.
Utilisez des méthodes telles que la recherche par grille ou la recherche aléatoire pour trouver l'ensemble optimal d'hyperparamètres.
Backtesting
Tester les performances du modèle par rapport à des données historiques (backtesting).
Assurez-vous que le modèle est robuste et qu'il fonctionne bien sur différentes périodes et dans différentes conditions de marché.
Intégrer des stratégies de gestion des risques
Inclure des mesures pour tenir compte du risque de modèle, du risque de marché et d'autres risques financiers.
Mettre en œuvre des stratégies telles que la sortie de position ou le dimensionnement de la position sur la base des intervalles de confiance du modèle.
Déploiement
Intégrer le modèle dans la plateforme souhaitée pour un traitement en temps réel ou par lots.
S'assurer que le modèle a accès à des flux de données en temps réel pour les prédictions en direct.
Suivi et mise à jour
Contrôler en permanence les performances du modèle.
Mettez régulièrement le modèle à jour avec de nouvelles données et ajustez-le en fonction de l'évolution des conditions du marché ou de l'apparition de nouveaux critères pertinents à tester.
Documentation et conformité
Documentez soigneusement le modèle, y compris sa conception, ses sources de données, ses hypothèses et ses limites.
Veillez à ce que le modèle soit conforme aux normes réglementaires et éthiques applicables.
Exemples de variables à inclure
Se concentrer sur les variables macroéconomiques pour prévoir les taux de change implique une sélection minutieuse des indicateurs susceptibles d'influencer la valeur de la monnaie.
Voici une liste de variables macroéconomiques clés que vous devriez envisager d'intégrer dans votre modèle (si vous choisissez de poursuivre cette approche fondamentale à long terme) :
Taux d'intérêt
Les banques centrales influencent les taux de change en contrôlant les taux d'intérêt.
Des taux d'intérêt plus élevés offrent aux prêteurs un rendement supérieur à celui des autres pays, ce qui attire les capitaux étrangers et entraîne une hausse du taux de change.
Taux d'inflation
En règle générale, les pays dont les taux d'inflation sont constamment bas voient la valeur de leur monnaie augmenter, car leur pouvoir d'achat s'accroît par rapport à celui des autres monnaies.
Inversement, une inflation plus élevée déprécie généralement la valeur d'une monnaie par rapport aux monnaies de ses partenaires commerciaux.
Produit intérieur brut (PIB)
Le PIB est un indicateur essentiel de la santé économique d'un pays.
Un taux de croissance élevé du PIB renforce souvent la monnaie du pays concerné, car il implique une économie robuste.
Balance des comptes courants
Le compte courant reflète la balance commerciale du pays, les revenus des investissements étrangers et les transferts de fonds.
Un excédent de la balance courante indique que le pays est un prêteur net au reste du monde, ce qui peut renforcer sa monnaie.
Dette publique
Les pays fortement endettés sont moins susceptibles d'attirer les investissements étrangers, ce qui entraîne une baisse de la valeur de la monnaie.
Une dette élevée peut entraîner une inflation - c'est-à-dire une augmentation de la charge de la dette, qui peut être indésirable et conduire à des taux d'intérêt plus élevés pour aider à assainir le marché - ce qui peut déprécier la monnaie.
Stabilité politique et performance économique
Les pays qui sont politiquement stables et qui ont de bonnes performances économiques ont tendance à attirer les investisseurs étrangers.
La stabilité politique et économique influence la confiance des investisseurs étrangers, ce qui a un impact sur la valeur de la monnaie.
Termes de l'échange
Les variations des prix à l'exportation et à l'importation ont un impact sur les termes de l'échange.
Si le prix des exportations d'un pays augmente par rapport à celui de ses importations, ses termes de l'échange se sont améliorés, ce qui accroît ses revenus et entraîne une hausse de la valeur de sa monnaie.
Indicateurs d'emploi
Les niveaux d'emploi dans une économie affectent les dépenses de consommation et la croissance économique.
Un taux d'emploi plus élevé se traduit généralement par une économie plus forte et, potentiellement, par une monnaie plus forte.
Déclarations de politique monétaire
Les communications et les déclarations des banques centrales peuvent avoir des effets immédiats sur les marchés des changes, car elles contiennent souvent des indications sur la politique monétaire future.
Réserves de change
Le montant des réserves d'une devise détenues par des gouvernements étrangers peut affecter la valeur de la devise.
Des réserves importantes de devises étrangères peuvent être utilisées pour stabiliser la monnaie nationale.
Flux de capitaux
Ils comprennent les investissements directs étrangers (IDE) et les investissements de portefeuille.
Les flux de capitaux entrant et sortant d'un pays peuvent influencer les taux de change car ils modifient la demande de la monnaie nationale.
Indicateurs économiques mondiaux
L'économie étant interconnectée au niveau mondial, les indicateurs économiques internationaux peuvent également avoir un impact sur les taux de change.
Il s'agit notamment des indicateurs de santé économique des principaux partenaires commerciaux ou des entités économiques mondiales telles que l'Union européenne, la Chine ou les États-Unis.
Résumé
L'intégration de ces variables dans votre modèle implique une collecte, un traitement et une analyse minutieux des données.
La relation entre ces variables et les taux de change peut être complexe et non linéaire.
Cela peut nécessiter des techniques statistiques avancées et des algorithmes d'apprentissage automatique pour une modélisation et une prédiction précises.
En outre, l'importance et l'impact de chaque variable peuvent varier en fonction de la paire de devises spécifique et du contexte économique analysé.
Méthodes mathématiques, statistiques et algorithmiques
Pour prévoir les taux de change à l'aide de variables macroéconomiques, il est possible d'utiliser un mélange de techniques mathématiques, statistiques et algorithmiques.
Étant donné la complexité et la nature dynamique des marchés financiers, il est essentiel d'utiliser des méthodes sophistiquées capables de saisir les relations complexes entre les différentes variables et leur impact sur les taux de change.
Voici quelques techniques clés :
Analyse des séries temporelles
ARIMA (Moyenne mobile intégrée autorégressive)
Utile pour modéliser les données de séries temporelles, en particulier pour les prévisions basées sur des données historiques.
VAR (autorégression vectorielle)
Généralisation de l'ARIMA permettant de modéliser les interdépendances entre plusieurs séries temporelles (par exemple, différents indicateurs macroéconomiques).
GARCH (Hétéroscédasticité conditionnelle autorégressive généralisée)
Efficace pour modéliser les séries temporelles financières qui présentent des grappes de volatilité, une caractéristique commune aux données sur les taux de change (et généralement à toutes les données sur les actifs).
Algorithmes d'apprentissage automatique
Forêt aléatoire
Méthode d'apprentissage ensembliste pour la classification et la régression, capable de traiter un grand nombre de caractéristiques et d'identifier les variables importantes.
Machines à vecteurs de support (SVM)
Efficaces dans les espaces à haute dimension, les SVM conviennent aux ensembles de données dont le nombre de dimensions est supérieur au nombre d'échantillons.
Réseaux neuronaux et apprentissage profond
En particulier les réseaux LSTM (Long Short-Term Memory), qui sont aptes à capturer les dépendances à long terme dans les données de séries temporelles.
Modèles économétriques
Analyse de cointégration
Cette analyse teste l'existence d'une relation d'équilibre à long terme entre les taux de change et les variables macroéconomiques.
Modèles de données en panel
Si vous analysez des données qui s'étendent sur différents pays ou périodes, les modèles de données de panel tels que les modèles à effets fixes ou à effets aléatoires peuvent s'avérer utiles.
Techniques statistiques
Analyse en composantes principales (ACP)
Pour réduire la dimensionnalité et identifier les facteurs sous-jacents qui expliquent la variance des taux de change.
Tests de causalité de Granger
Pour vérifier si une série temporelle peut en prédire une autre.
Ceci est important pour établir des relations entre les variables macroéconomiques et les taux de change.
Méthodes bayésiennes
Modèles de régression bayésiens
Utile pour traiter de petits ensembles de données ou pour incorporer des croyances ou des informations préalables dans l'analyse.
Chaîne de Markov Monte Carlo (MCMC)
Pour les modèles complexes où l'inférence traditionnelle est difficile, MCMC fournit des méthodes d'échantillonnage à partir de distributions de probabilité.
Techniques d'optimisation
Descente de gradient et ses variantes (par exemple, descente de gradient stochastique)
Pour optimiser les paramètres des modèles d'apprentissage automatique, en particulier les réseaux neuronaux.
Algorithmes génétiques
Utiles pour optimiser la sélection des caractéristiques et les paramètres des modèles dans des problèmes complexes et non linéaires.
Voir aussi : Méthodes heuristiques et métaheuristiques
Méthodes de régularisation
Régression en crête (régularisation L2)
Pour éviter l'ajustement excessif en pénalisant les coefficients importants.
Régression Lasso (régularisation L1)
Utile pour la sélection des caractéristiques car elle permet de réduire à zéro les coefficients des variables les moins importantes.
Analyse des sentiments et traitement du langage naturel (NLP)
Pour intégrer des données qualitatives provenant d'articles de presse, de rapports ou de médias sociaux, qui peuvent avoir un impact sur les taux de change.
Résumé
Chacune de ces techniques offre des avantages distincts et peut être choisie en fonction des caractéristiques spécifiques de votre ensemble de données, de la complexité du modèle et des objectifs de prédiction.
Souvent, une approche hybride combinant plusieurs techniques peut donner de meilleurs résultats.
À tout le moins, elle peut vous aider à trianguler.
Exemple d'algorithme
La création d'un modèle complet de prévision des taux de change implique plusieurs étapes, notamment la collecte des données, le prétraitement, la sélection des caractéristiques, la construction du modèle et l'évaluation.
Cet exemple suppose que vous disposiez d'un ensemble de données contenant des taux de change historiques et les variables macroéconomiques correspondantes.
Nous utiliserons une approche d'apprentissage automatique avec un régresseur Random Forest pour cet exemple.
Partie 1 : Importer les bibliothèques et charger les données
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
import matplotlib.pyplot as plt
# Chargez votre jeu de données, qui doit contenir des taux de change historiques et des variables macroéconomiques.
# Remplacer 'your_dataset.csv' par votre fichier de données actuel
data = pd.read_csv('your_dataset.csv')Partie 2 : Prétraitement des données
# En supposant que l'ensemble de données comporte des colonnes telles que "taux de change", "taux d'intérêt", "taux d'inflation", etc.
# Check for missing values
data = data.dropna()
# Séparer les caractéristiques et la variable cible
X = data.drop('exchange_rate', axis=1) # Features (Macroeconomic Variables)
y = data['exchange_rate'] # Target Variable
# Diviser l'ensemble de données en deux ensembles, l'un pour la formation et l'autre pour le test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)Partie 3 : Construction du modèle
# Démarrer le régresseur Random Forest
rf_model = RandomForestRegressor(n_estimators=100, random_state=42)
# Former le modèle
rf_model.fit(X_train, y_train)Partie 4 : Évaluation du modèle
# Prévoir les taux de change
y_pred = rf_model.predict(X_test)
# Calculer l'erreur quadratique moyenne
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse}")
# Tracer les valeurs prédites par rapport aux valeurs réelles
plt.scatter(y_test, y_pred)
plt.xlabel('Actual Exchange Rates')
plt.ylabel('Predicted Exchange Rates')
plt.title('Predicted vs Actual Exchange Rates')
plt.show()Comme cet exemple est un peu abstrait sans les données, concevons-en un avec des données synthétiques et incluons les macro-variables que nous avons couvertes plus haut :
# Définir une graine aléatoire
np.random.seed(55)
# Nombre d'échantillons
n_samples = 1000
# Générer des caractéristiques synthétiques
interest_rates = np.random.normal(2, 0.5, n_samples) # Interest Rates
inflation_rates = np.random.normal(2, 1, n_samples) # Inflation Rates
gdp_growth = np.random.normal(3, 1, n_samples) # GDP Growth
current_account_balance = np.random.normal(0, 1, n_samples) # Current Account Balance
government_debt = np.random.normal(50, 10, n_samples) # Government Debt
political_stability = np.random.choice([0, 1], size=n_samples, p=[0.3, 0.7]) # Political Stability (0: unstable, 1: stable)
terms_of_trade = np.random.normal(100, 20, n_samples) # Terms of Trade
employment_rate = np.random.normal(5, 1, n_samples) # Employment Rate
monetary_policy_statements = np.random.choice([0, 1, 2], size=n_samples, p=[0.3, 0.4, 0.3]) # Monetary Policy (0: tightening, 1: neutral, 2: loosening)
foreign_exchange_reserves = np.random.normal(100, 25, n_samples) # Foreign Exchange Reserves
capital_flows = np.random.normal(0, 1, n_samples) # Capital Flows
# Génération d'une variable cible synthétique (taux de change)
# La formule utilisée ici est hypothétique et a pour but d'illustrer la situation.
exchange_rates = 50 + 1.5*interest_rates - 2*inflation_rates + 1.2*gdp_growth + 0.5*current_account_balance - \
0.3*government_debt + 2*political_stability + 0.1*terms_of_trade - 0.5*employment_rate + \
0.4*monetary_policy_statements + 0.2*foreign_exchange_reserves + 0.3*capital_flows + \
np.random.normal(0, 2, n_samples)
# Création du DataFrame
data = pd.DataFrame({
'Interest Rates': interest_rates,
'Inflation Rates': inflation_rates,
'GDP Growth': gdp_growth,
'Current Account Balance': current_account_balance,
'Government Debt': government_debt,
'Political Stability': political_stability,
'Terms of Trade': terms_of_trade,
'Employment Rate': employment_rate,
'Monetary Policy Statements': monetary_policy_statements,
'Foreign Exchange Reserves': foreign_exchange_reserves,
'Capital Flows': capital_flows,
'Exchange Rates': exchange_rates
})
# Fractionnement de l'ensemble de données
X = data.drop('Exchange Rates', axis=1)
y = data['Exchange Rates']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=10)
# Construction du modèle Random Forest
rf_model = RandomForestRegressor(n_estimators=100, random_state=10)
rf_model.fit(X_train, y_train)
# Prévoir et évaluer
y_pred = rf_model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
mse
y_pred #Will give you an array of valuesIl en ressort que ce modèle Random Forest, entraîné sur un ensemble de données synthétiques incorporant un large éventail de variables macroéconomiques, produit une erreur quadratique moyenne (EQM) d'environ 7,76.
Cette valeur représente la différence quadratique moyenne entre les taux de change réels et prédits dans notre ensemble de données synthétiques.
Cette valeur est raisonnable si l'on considère que le taux de change a tendance à osciller entre 50 et 80 et en fonction du nombre de variables dans notre modèle.
Dans quelle mesure les taux de change prédits correspondent-ils aux taux de change réels ?
Nous pouvons établir un graphique à cet effet :
plt.figure(figsize=(10, 6))
# Réel vs Prévision
plt.scatter(range(len(plot_data)), plot_data['Actual'], label='Actual Exchange Rates', color='red', alpha=0.7)
plt.scatter(range(len(plot_data)), plot_data['Predicted'], label='Predicted Exchange Rates', color='blue', alpha=0.7)
# Intervalle de confiance
plt.fill_between(range(len(plot_data)), plot_data['Lower Bound'], plot_data['Upper Bound'], color='skyblue', alpha=0.4)
# Ajout de titres et d'étiquettes
plt.title('Exchange Rate Prediction with Confidence Intervals')
plt.xlabel('Data Points')
plt.ylabel('Exchange Rate')
plt.legend()
plt.show()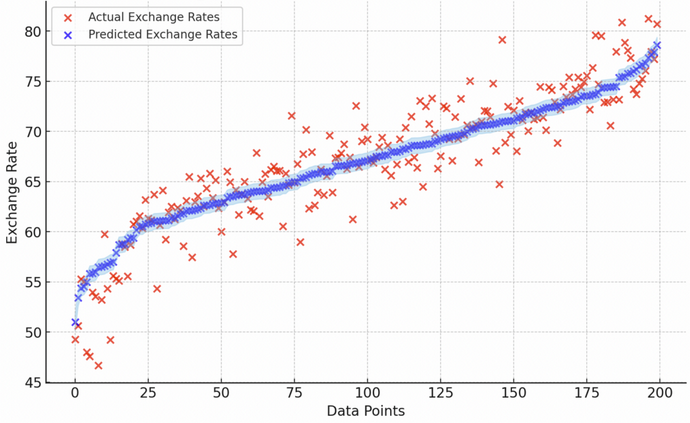
Prédiction du taux de change avec intervalles de confiance
Le graphique utilise des points bleus pour représenter les taux de change prédits et des points rouges pour les taux de change réels.
Le nuage bleu autour des prédictions illustre les intervalles de confiance.
Cette visualisation compare chaque taux de change prédit avec le taux réel correspondant.
La proximité des points bleus et des points rouges indique à quel point les prédictions sont proches des valeurs réelles.
L'intervalle de confiance (nuage bleu) donne un aperçu de l'incertitude ou de la variabilité entourant chaque prédiction.
Modèles d'apprentissage automatique pour les systèmes de trading de devises et détection de variables cachées
Le trading de devises est complexe parce qu'il y a beaucoup de variables et qu'il est difficile de tout saisir.
De plus, le poids de chaque variable varie.
Par exemple, les envois de fonds ont des effets plus importants sur les taux de change des monnaies des pays émergents que sur les monnaies de réserve comme l'USD.
Pour améliorer la prédiction des valeurs monétaires et identifier les variables cachées dans les données financières, plusieurs techniques avancées d'apprentissage automatique peuvent être exploitées au-delà des méthodes d'apprentissage non supervisé de base telles que le regroupement et l'analyse en composantes principales (ACP).
Ces techniques sont conçues pour gérer la complexité et la non-linéarité des marchés financiers :
Apprentissage supervisé
Analyse de régression
Des techniques de régression avancées, telles que Ridge, Lasso et Elastic Net, peuvent être utilisées pour la sélection des caractéristiques et la régularisation afin de gérer la multicolinéarité et le surajustement tout en identifiant les variables les plus influentes.
Arbres de décision et forêts aléatoires
Ils peuvent être utilisés pour les tâches de classification et de régression.
Les forêts aléatoires, un ensemble d'arbres de décision, permettent de capturer les relations non linéaires et les interactions entre les variables.
Apprentissage non supervisé
Autoencodeurs
Type de réseau neuronal utilisé pour l'apprentissage non supervisé de codages efficaces.
Les autoencodeurs peuvent aider à identifier des relations complexes et non linéaires dans les données et potentiellement suggérer des variables cachées à travers l'erreur de reconstruction.
t-Distributed Stochastic Neighbor Embedding (t-SNE) (intégration des voisins stochastiques distribués)
Cette technique est utile pour visualiser des données de haute dimension dans des espaces de dimension inférieure, ce qui peut aider à identifier des grappes ou des modèles qui suggèrent des variables manquantes.
Apprentissage semi-supervisé
Les techniques qui exploitent à la fois les données étiquetées et non étiquetées peuvent être particulièrement utiles lorsque la quantité de données étiquetées disponibles est limitée.
Cette approche peut aider à identifier des structures ou des modèles sous-jacents qui ne sont pas évidents lorsqu'on utilise uniquement des données étiquetées ou non étiquetées.
Apprentissage par renforcement
Bien qu'il soit traditionnellement utilisé pour les processus de prise de décision, l'apprentissage par renforcement peut également être appliqué pour identifier des stratégies permettant de prédire efficacement la valeur des devises.
Il permet de s'adapter à de nouvelles données et de découvrir des variables cachées grâce à l'exploration.
Apprentissage en profondeur
Réseaux neuronaux convolutifs
Principalement utilisés pour le traitement d'images, les réseaux neuronaux convolutifs peuvent également être appliqués aux données de séries temporelles afin de saisir les hiérarchies spatiales dans les données et d'identifier des modèles complexes dans le temps.
Réseaux neuronaux récurrents (RNN) et réseaux à mémoire à long terme
Ils sont particulièrement adaptés aux données séquentielles telles que les séries temporelles, capables d'apprendre les dépendances à long terme et d'identifier des schémas que des modèles plus simples pourraient manquer.
Réseaux neuronaux graphiques
Pour les données financières structurées sous forme de graphiques (par exemple, les réseaux de prêts interbancaires), les réseaux neuronaux graphiques peuvent capturer les relations et les interactions entre les entités, ce qui peut permettre de découvrir des variables cachées qui influencent la valeur des devises.
Méthodes bayésiennes
Processus gaussiens
Ils peuvent être utilisés pour les tâches de régression et de classification, qui offrent une approche probabiliste de l'apprentissage.
Les processus gaussiens sont utiles pour modéliser l'incertitude, ce qui peut aider à identifier quand de nouvelles variables non prises en compte peuvent influencer les prédictions.
Méthodes d'ensemble
Boosting (par exemple, XGBoost, LightGBM, AdaBoost)
Ces techniques combinent plusieurs apprenants faibles pour créer un modèle prédictif fort.
Elles sont utiles pour améliorer les performances et la stabilité des modèles et peuvent mettre en évidence les caractéristiques (variables) qui contribuent le plus à la prédiction des valeurs monétaires.
Résumé
Chacune de ces techniques a ses points forts et peut être particulièrement adaptée à différents aspects de l'analyse des données financières.
Le choix de la technique dépend des éléments suivants
des caractéristiques spécifiques des données
des ressources informatiques disponibles, et
de la complexité des relations entre les variables dans la prédiction des valeurs monétaires.
Conclusion
Cet algorithme, s'il est bien conçu et rigoureusement testé, peut servir d'outil de prévision des taux de change.
Il peut aider les institutions financières, les négociants et les décideurs à prendre des décisions stratégiques.

Le trading de CFD implique un risque de perte significatif, il ne convient donc pas à tous les investisseurs. 70 à 80% des comptes d'investisseurs particuliers perdent de l'argent en négociant des CFD.
Hors ligne
- Utilisateurs enregistrés en ligne dans ce sujet: 0, invités: 1
- [Bot] ClaudeBot