Vous n'êtes pas identifié(e).
- Contributions: Récentes | Sans réponse
#1 15-12-2023 14:31:39
- Climax
- Administrateur

- Inscription: 30-08-2008
- Messages: 6 378


La théorie de l'estimation en finance
La théorie de l'estimation est une branche de la statistique qui permet de déduire les valeurs des paramètres inconnus dans les modèles financiers.
Ce processus implique l'utilisation de méthodes statistiques pour estimer ces paramètres sur la base de données observées.
La théorie de l'estimation peut être utilisée dans l'évaluation des actifs, la gestion des risques, la construction de portefeuilles et divers autres domaines de la finance quantitative.
Principaux enseignements :
➡️ Concept fondamental des estimateurs sans biais :
La théorie de l'estimation souligne l'importance de l'utilisation d'estimateurs sans biais dans l'analyse statistique.
Elle garantit que la valeur attendue de ces estimateurs correspond aux véritables valeurs des paramètres.
Permet d'obtenir des estimations précises et fiables sur de nombreux échantillons.
➡️ Efficacité et cohérence :
La théorie donne la priorité à l'efficacité. Cela signifie que parmi les estimateurs sans biais, ceux dont la variance est la plus faible sont privilégiés.
La cohérence est également importante. Elle garantit qu'à mesure que la taille de l'échantillon augmente, l'estimateur converge en probabilité vers la vraie valeur du paramètre.
➡️ Rôle de l'estimation du maximum de vraisemblance (EMV) :
L'estimation du maximum de vraisemblance est une technique centrale de la théorie de l'estimation. Elle fournit une méthode d'estimation des paramètres d'un modèle statistique.
Elle sélectionne les valeurs des paramètres qui maximisent la fonction de vraisemblance, ce qui permet souvent d'obtenir des estimateurs plus précis et plus efficaces dans de nombreuses applications pratiques.
➡️ Exemples
Nous utilisons ci-dessous des exemples de régression linéaire et de simulations de Monte Carlo.
Principes fondamentaux de la théorie de l'estimation
Comprendre les estimateurs statistiques
Un estimateur statistique est un algorithme ou une formule qui aide à déduire les paramètres inconnus d'une population donnée à partir de données observées.
En finance, ces estimateurs permettent de faire des déductions sur les rendements du marché, la volatilité, les corrélations et d'autres paramètres financiers.
Types d'estimateurs
Deux types principaux d'estimateurs sont largement utilisés :
les estimateurs ponctuels
les estimateurs d'intervalles
Les estimateurs ponctuels fournissent une estimation à valeur unique d'un paramètre de population, comme le rendement moyen d'une action.
Les estimateurs d'intervalle, quant à eux, proposent une fourchette dans laquelle le paramètre est censé se situer, en tenant compte de l'incertitude et de la variabilité des données.
Application de la théorie de l'estimation à la finance
Modèles d'évaluation des actifs
La théorie de l'estimation joue un rôle essentiel dans le développement et le perfectionnement des modèles d'évaluation des actifs tels que le modèle d'évaluation des actifs financiers (CAPM) et la théorie de l'évaluation des arbitrages (APT).
Elle aide à estimer les paramètres tels que le bêta dans le CAPM, qui mesure la volatilité d'une action par rapport au marché.
Gestion du risque
Dans la gestion des risques, la théorie de l'estimation est utilisée pour quantifier les mesures de risque telles que la valeur à risque (VaR) et la valeur à risque conditionnelle (CVaR).
Les estimateurs aident à évaluer la probabilité de pertes financières dans des conditions de marché normales et extrêmes.
Optimisation de portefeuille
L'optimisation de portefeuille s'appuie fortement sur la théorie de l'estimation pour déterminer l'allocation optimale des actifs.
Les estimateurs sont utilisés pour évaluer les rendements attendus, les variances et les covariances des rendements des actifs, ce qui est important pour construire des portefeuilles efficaces.
Les défis de la théorie de l'estimation
Qualité et disponibilité des données
La précision des estimateurs dépend fortement de la qualité et de la quantité des données disponibles.
Sur les marchés financiers, il s'agit notamment de traiter des ensembles de données bruyantes, non stationnaires et parfois incomplètes.
Hypothèses du modèle
De nombreux modèles financiers basés sur la théorie de l'estimation reposent sur des hypothèses spécifiques telles que la normalité des rendements ou des relations linéaires entre les variables.
La violation de ces hypothèses peut conduire à des estimations biaisées ou incohérentes.
De nombreux rendements sont à queue large ou ne correspondent pas parfaitement à une approche paramétrique.
Ajustement excessif et ajustement insuffisant
Il existe un équilibre dans la complexité des modèles.
Le surajustement consiste à créer des modèles trop complexes qui s'adaptent au bruit des données.
Les modèles sous-adaptés sont trop simplistes pour saisir la dynamique sous-jacente des marchés financiers.
L'avenir de la théorie de l'estimation en finance
Les progrès de la puissance de calcul et des algorithmes d'apprentissage automatique élargissent les horizons de la théorie de l'estimation en finance.
Des techniques telles que l'estimation bayésienne, les simulations de Monte Carlo et les modèles d'apprentissage automatique sont de plus en plus souvent adoptées pour les données financières et fournissent des estimations plus robustes et plus précises.
L'avenir de l'estimation en finance est orienté vers des modèles plus adaptatifs, basés sur des données et capables de gérer les différentes nuances des marchés financiers (par exemple, l'apprentissage automatique).
Théorie de l'estimation - Code Python (Simulation Monte Carlo)
La simulation de Monte Carlo, telle qu'elle est présentée dans le code Python, teste à terme la distribution d'un portefeuille spécifique sur une année.
Le portefeuille se compose d'actions, d'obligations, de liquidités et d'or, avec des allocations prédéterminées et leurs rendements et volatilités attendus respectifs.
Les principaux aspects de cette simulation sont les suivants :
Composition du portefeuille
Le portefeuille est composé de quatre actifs :
35 % Actions
40% Obligations
10 % de liquidités
15 % d'or
Chaque classe d'actifs a son propre rendement attendu à terme et sa propre volatilité annualisée (à l'exception des liquidités, dont la volatilité est nulle).
Actions : Rendement à terme de 6 %, volatilité annualisée de 15 % en utilisant l'écart-type
Obligations : 3,5 % de rendement à terme, 10 % de volatilité annualisée en utilisant l'écart-type
Liquidités : 3% de rendement à terme, 0% de volatilité annualisée en utilisant l'écart-type
Or : 3% de rendement à terme, 15% de volatilité annualisée en utilisant l'écart-type
Paramètres de simulation
La simulation effectue 10 000 itérations afin de générer un large éventail de résultats possibles.
L'horizon temporel est fixé à un an et l'investissement initial est de 100 000 $.
Processus de simulation
Pour chaque itération, la valeur finale du portefeuille est calculée en appliquant le rendement et la volatilité de chaque classe d'actifs, compte tenu de leurs allocations respectives.
L'hypothèse de non-corrélation des actifs est maintenue tout au long de la simulation.
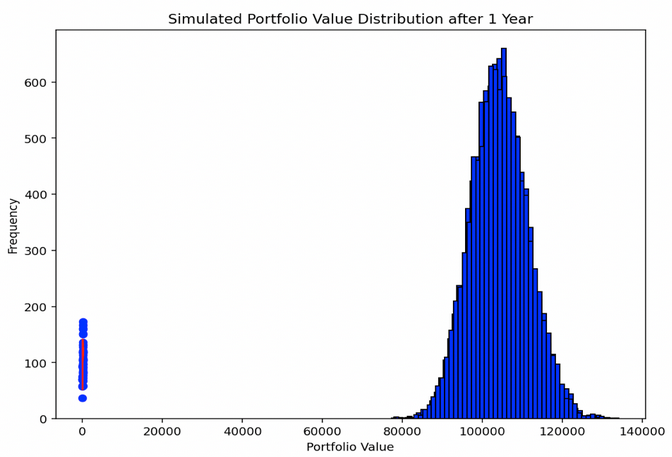
Visualisation des résultats
L'histogramme affiche la distribution des valeurs finales du portefeuille pour l'ensemble des simulations.
Cette distribution donne un aperçu de l'étendue et de la probabilité des différents résultats du portefeuille après un an, compte tenu de l'allocation d'actifs spécifique et des conditions de marché définies pour chaque classe d'actifs.
Cette simulation permet de comprendre le profil de risque et de rendement potentiel d'un portefeuille donné.
Voici le code :
import numpy as np
import matplotlib.pyplot as plt
# Monte Carlo simulation for forward testing a specific portfolio's distribution
# Portfolio composition with their specific allocations, expected returns, and volatilities
portfolio = {
"Stocks": {"allocation": 0.35, "return": 0.06, "volatility": 0.15},
"Bonds": {"allocation": 0.40, "return": 0.035, "volatility": 0.10},
"Cash": {"allocation": 0.10, "return": 0.03, "volatility": 0},
"Gold": {"allocation": 0.15, "return": 0.03, "volatility": 0.15}
}
# Simulation parameters
num_simulations = 10000 # Number of Monte Carlo simulations
time_horizon = 1 # Time horizon for the simulation (1 year)
initial_investment = 100000 # Initial investment amount
# Simulating portfolio value over the time horizon
portfolio_values = np.zeros(num_simulations)
np.random.seed(0) # For reproducibility
for i in range(num_simulations):
final_value = initial_investment
# Calculating portfolio value at the end of time horizon for each asset
for asset, info in portfolio.items():
annual_return = info["return"]
annual_volatility = info["volatility"]
random_return = np.random.normal(annual_return, annual_volatility)
final_value += final_value * info["allocation"] * random_return
portfolio_values[i] = final_value
# Plotting the distribution of portfolio values
plt.hist(portfolio_values, bins=50, color='blue', edgecolor='black')
plt.title('Simulated Portfolio Value Distribution after 1 Year')
plt.xlabel('Portfolio Value')
plt.ylabel('Frequency')
plt.show()Si vous utilisez ce code, veillez à l'indenter aux endroits appropriés, car l'indentation est importante en Python :
Théorie de l'estimation - Code Python (Régression linéaire)
Dans cet exemple, la régression linéaire est appliquée pour comprendre la relation entre les bénéfices d'une entreprise et le cours de son action :
Génération de données synthétiques
Des données synthétiques sont créées pour les bénéfices (en millions de dollars) et les prix des actions de 50 entreprises.
Les bénéfices sont normalement distribués et les cours des actions sont modélisés pour être liés à ces bénéfices.
Modèle de régression linéaire
Le modèle de régression linéaire est ajusté à ces données, les bénéfices étant la variable indépendante et les cours des actions la variable dépendante.
Estimation de la relation
Le coefficient obtenu à partir du modèle indique la relation entre les bénéfices et les cours boursiers.
Dans ce contexte, il représente l'augmentation attendue du prix des actions pour chaque million de dollars d'augmentation des bénéfices.
Visualisation
Un diagramme de dispersion est représenté avec les bénéfices en abscisse et les cours des actions en ordonnée, ainsi que la droite de régression.
Ce diagramme permet de visualiser la corrélation entre les bénéfices d'une entreprise et le cours de ses actions.
Cette analyse montre comment la théorie de l'estimation, par le biais de la régression linéaire, peut être utilisée en finance pour comprendre et quantifier les relations entre différentes mesures financières.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
# Generating synthetic data for stock prices and earnings
np.random.seed(0)
companies = 50
earnings = np.random.normal(50, 10, companies) # Earnings in million dollars
stock_prices = earnings * np.random.normal(2, 0.5, companies) # Stock price related to earnings
# Creating a DataFrame
data = pd.DataFrame({'Earnings': earnings, 'Stock_Prices': stock_prices})
# Applying Linear Regression
model = LinearRegression()
model.fit(data[['Earnings']], data['Stock_Prices'])
# Estimating the relationship
relationship = model.coef_[0]
# Plotting
plt.scatter(data['Earnings'], data['Stock_Prices'], color='blue')
plt.plot(data['Earnings'], model.predict(data[['Earnings']]), color='red')
plt.title('Stock Prices vs Earnings')
plt.xlabel('Earnings (Million Dollars)')
plt.ylabel('Stock Prices')
plt.show()
relationship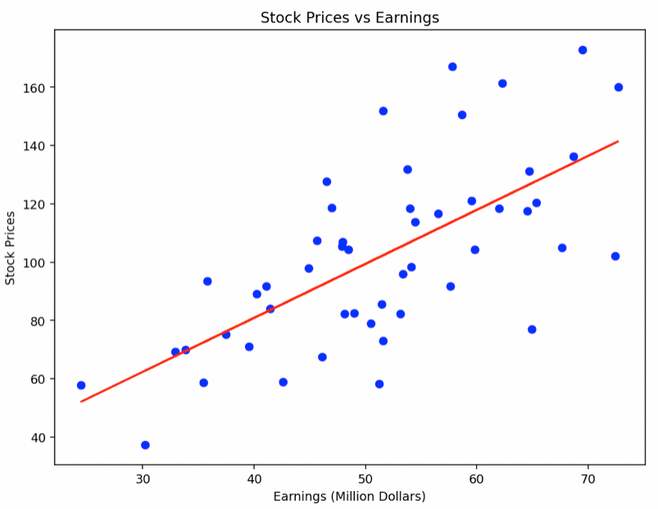
FAQ - Théorie de l'estimation
Qu'est-ce que la théorie de l'estimation en finance ?
La théorie de l'estimation en finance implique l'utilisation de méthodes statistiques pour déterminer les paramètres inconnus des modèles financiers sur la base des données observées.
Elle permet de faire des suppositions éclairées sur des paramètres financiers importants, comme les rendements boursiers ou la volatilité du marché.
Cette théorie est importante dans des domaines tels que l'évaluation des actifs, la gestion des risques et l'optimisation des portefeuilles, où des estimations précises guident les décisions d'investissement et l'évaluation des risques.
Comment la théorie de l'estimation fonctionne-t-elle dans les modèles d'évaluation des actifs ?
La théorie de l'estimation dans les modèles d'évaluation des actifs implique le calcul de paramètres tels que le bêta dans le modèle d'évaluation des actifs financiers (CAPM), qui indique le risque d'une action par rapport au marché.
Elle permet d'estimer les rendements attendus sur la base de données historiques, en tenant compte de facteurs tels que la prime de risque du marché et le taux sans risque.
La théorie de l'estimation permet aux traders, aux investisseurs et aux analystes de prendre des décisions éclairées sur la base des comportements historiques du marché et des analyses statistiques.
Comment la théorie de l'estimation contribue-t-elle à la gestion des risques en finance ?
Dans la gestion des risques, la théorie de l'estimation est essentielle pour quantifier les mesures de risque telles que la valeur à risque (VaR) et la valeur à risque conditionnelle (CVaR).
Ces mesures évaluent les pertes potentielles d'un portefeuille, en tenant compte des tendances historiques du marché et de la volatilité.
La théorie de l'estimation permet de prévoir la probabilité et l'ampleur des pertes dans différentes conditions de marché.
Elle aide les gestionnaires de risques à élaborer des stratégies visant à atténuer les risques financiers potentiels et à comprendre le compromis risque-rendement dans leurs choix.
Quelles sont les méthodes statistiques les plus couramment utilisées dans l'estimation financière ?
Les méthodes statistiques courantes en matière d'estimation financière comprennent l'analyse de régression, l'analyse des séries chronologiques et les simulations de Monte Carlo.
L'analyse de régression est utilisée pour comprendre les relations entre les variables financières.
L'analyse des séries temporelles permet de prévoir les tendances futures du marché sur la base des données passées.
Les simulations de Monte Carlo sont utilisées pour évaluer l'impact du risque et de l'incertitude dans les modèles financiers en simulant un large éventail de résultats possibles (et sont de nature non paramétrique).
Ces méthodes fournissent un cadre pour l'analyse de données financières complexes et la réalisation d'estimations éclairées.
Comment la théorie de l'estimation contribue-t-elle à l'optimisation des portefeuilles ?
La théorie de l'estimation contribue à l'optimisation des portefeuilles en estimant les rendements attendus, les variances et les covariances des rendements des actifs.
Ces estimations sont fondamentales pour construire des portefeuilles efficients qui visent à maximiser les rendements pour un niveau de risque donné.
En utilisant des données historiques et des modèles statistiques, la théorie de l'estimation guide l'allocation des actifs dans un portefeuille, en équilibrant le compromis entre le risque et le rendement, et aide à atteindre la diversification pour réduire le risque global du portefeuille.
Quelles sont les limites et les difficultés de l'utilisation de la théorie de l'estimation en analyse financière ?
Les limites et les défis de l'utilisation de la théorie de l'estimation dans l'analyse financière comprennent les problèmes de qualité des données, les hypothèses du modèle et le risque de surajustement ou de sous-ajustement.
Les données financières peuvent être bruyantes et non stationnaires, ce qui peut conduire à des estimations inexactes.
Les hypothèses telles que la normalité des rendements ou les relations linéaires ne se vérifient pas toujours, ce qui conduit à des estimations biaisées.
Le surajustement, lorsque les modèles capturent le bruit au lieu des tendances sous-jacentes, et le sous-ajustement, lorsque les modèles simplifient exagérément les données, sont des défis à relever.
Ces limites nécessitent une sélection minutieuse des modèles, leur validation et leur adaptation continue pour s'assurer qu'ils correspondent aux conditions actuelles (et futures) du marché.

Le trading de CFD implique un risque de perte significatif, il ne convient donc pas à tous les investisseurs. 70 à 80% des comptes d'investisseurs particuliers perdent de l'argent en négociant des CFD.
En ligne
- Utilisateurs enregistrés en ligne dans ce sujet: 0, invités: 1
- [Bot] ClaudeBot